
Monitoring Productivity II - the Others
In previous Monitoring Productivity Experiment post I looked into the hours I spent in computer, now I look into the hours Others spend in computer, which is far more interesting :) To find things like what day people spend more time on computer, how many hours they work, and general activity patterns.
Collecting data
In osx, is possible to use growl to display a message when a skype user signs in. So I configured growl to log the sign-in’s and sign-out’s of my skype contacts.
Like so:
> touch ~/Desktop/growl.log
> defaults write com.Growl.GrowlHelperApp GrowlLoggingEnabled -bool YES
> defaults write com.Growl.GrowlHelperApp GrowlLogType 1
> defaults write com.Growl.GrowlHelperApp "Custom log 1" ~/Desktop/growl.log
Instructions here.
And then I left my skype signed in for a few weeks, while I was on vacations.
Parsing data
Read the log file and create a semicolon separated file:
#!/usr/bin/env ruby
puts "timestamp;user;status"
File.open(ARGV[0]).each_line do |l|
if l.include? "online" or l.include? "offline"
date = l.split('Skype')[0].strip
user = l.scan(/Skype:([^\(]*)/)[0][0].strip
status = l.include?("online") ? "online" : "offline"
puts "#{date};#{user};#{status}"
end
end
Load it into R
data = read.csv("/my/proj/skype-growl/log.csv", sep=";", header=TRUE)
# parse dates "Aug 24, 2011 3:58:01 PM"
data$date = as.POSIXct(strptime(data$timestamp,"%b %d, %Y %I:%M:%S %p")) # DateTime
data$hour = format(data$date, format="%H:%M:%S") # string
data$time = as.POSIXct(data$hour, format = "%H:%M:%S") # DateTime
data$day = format(data$date, format="%m/%d/%y") # string
data$weekday = format(data$date, format="%A") # string
# filter for complete days of data
data = sqldf("select * from data where day >= '08/25/2011' and day <= '09/21/2011'")
sqldf("select count(distinct(day)) from data")
27 days of data.
The sign-in’s and sign-out’s of a random person
randomperson = sqldf("select user from data group by random() limit 1")
d = sqldf(sprintf("select *
from data
where user = '%s' and day >= '09/04/2011' and
day <= '09/12/2011'", randomperson[1,1]))
ggplot(data=d, aes(y=time, x=date)) + geom_point(aes(color=status), alpha=0.6) + scale_x_datetime(major = "1 days") + scale_y_datetime(major = "1 hours")
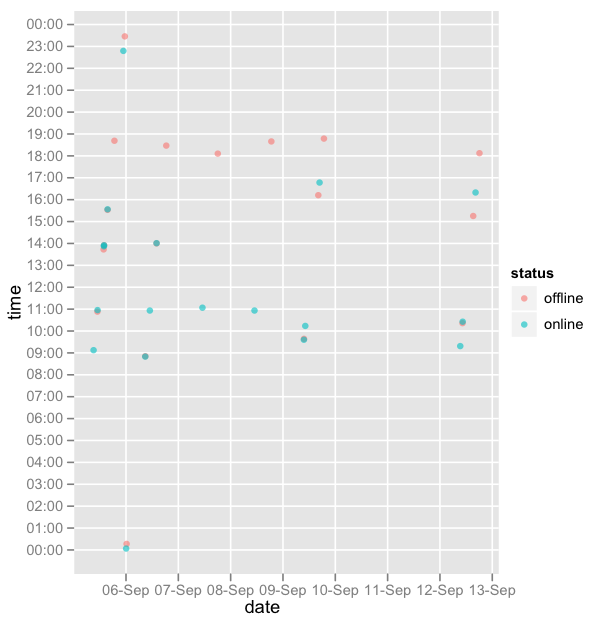
- 10-Sep is Saturday and 11-Sep is Sunday, means skype was off on the weekend
- start of workday between 9h-11h
- end of workday between 18h-19h
- skype is offline after working hours, except on night of Monday 05-Sep
Online Activity Patterns
Plotting all sign-in’s and sign-out’s over each weekday we can get a feeling for overall online activity:
ggplot(data, aes(x=time,..density..)) + geom_histogram() + facet_grid(weekday ~ .)
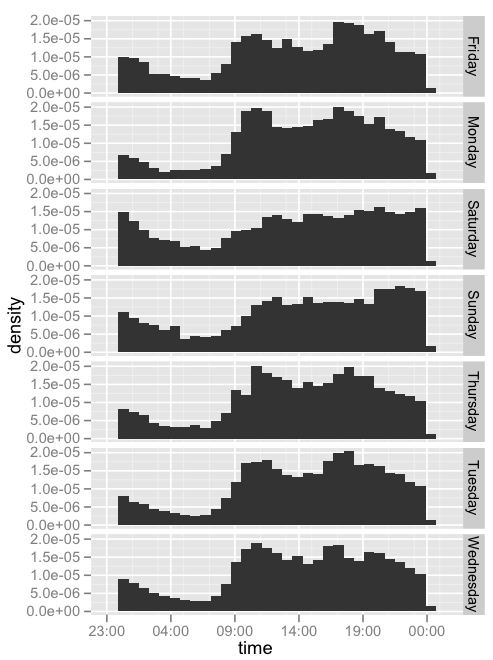
- Night time has less activity, and gets progressively smaller as night goes by
- Around 9am activity spikes (people start work?)
- Around 17h/18h activity spikes (people ending work?)
- The 9h & 17h spikes are not so well formed in the weekend, thus very likelly connected to work
- Sundays after dinner time(or so) people seems to start get online again before going to sleep
- On weekends computer gets more use later in the day
How many hours people work?
More tricky to accurately measure but we can have a guess:
- assuming that people are working during working hours of workdays
- assuming that nobody start works before 6am, and nobody ends work after 21pm
Then, the first activity after 6am is start of work, and the last activity change before 21pm is the end of work.
d = sqldf("select user,
day,
weekday,
min(hour) as start,
max(hour) as end
from data
where hour >= '06:00:00' and hour <= '21:00:00' and
weekday <> 'Saturday' and weekday <> 'Sunday'
group by user, day")
d$totalhours = difftime(as.POSIXct(d$end, format = "%H:%M:%S"), as.POSIXct(d$start, format = "%H:%M:%S"))
d$totalhours = as.numeric(d$totalhours, units="hours")
# excude less than 2 hours/day, means bots, vacations, etc...
dt = sqldf("select * from d where totalhours > 2")
al3x.load() # my own collection of R functions
al3x.hist(dt, "totalhours")
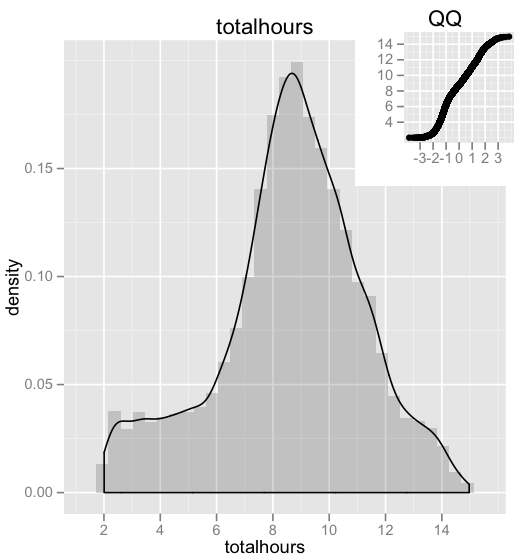
Workday total hours are mostly between 6 and 12 hours, most common being the 8.5 hours/day.
Which day people spend more time in computer?
We can try counting the amount of sign-in’s/sign-out’s changes per day, means people are more likely to be in computer.
d = sqldf("select weekday, count(status) as amount
from data
group by weekday
order by sum(time) DESC")
ggplot(d, aes(x=weekday,y=amount)) + geom_bar(stat="identity")
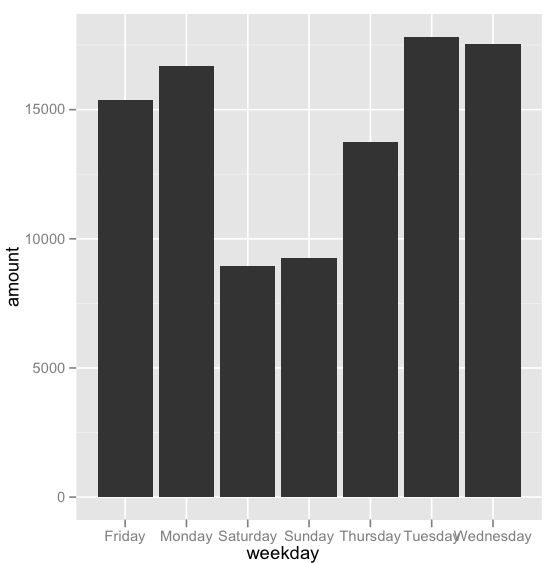
As the above could be biased in a number of ways lets use another way to measure it and if the results match then original estimate should be ok.
For example, way to go about it is to sum up the total working hours for each day:
d = sqldf("select user,
day,
weekday,
min(hour) as start,
max(hour) as end
from data
where hour >= '06:00:00' and hour <= '21:00:00'
group by user, day")
d$totalhours = difftime(as.POSIXct(d$end, format = "%H:%M:%S"), as.POSIXct(d$start, format = "%H:%M:%S"))
d$totalhours = as.numeric(d$totalhours, units="hours")
sqldf("select weekday, sum(totalhours) as amount
from d
group by weekday
order by sum(totalhours) DESC")
Getting:
weekday amount
1 Tuesday 15404.471
2 Wednesday 15191.946
3 Monday 14298.472
4 Friday 12426.091
5 Thursday 11638.443
6 Saturday 5222.874
7 Sunday 5198.367
Almost same results, great.
Thus Tuesday is the day people spend more time in computer, and in decreasing order:
Tuesday > Wednesday > Monday > Friday > Thursday > (Saturday or Sunday)
On productivity this means that Tuesday is the most productive day, while Thursday is the least.