
How to get into the Semantic Web
Practical examples on how to get onto the semantic web and on using it.
Getting in There
Start by creating a semantic web personal online profile using the Friend-Of-A-Friend (FOAF) vocabulary. The FOAF has became the standard for personal profiles on the semantic web, and as the name implies, it also lets you link to people you know.
I used the foaf-a-matic online tool and then uploaded the results to my site’s foaf.rdf. Easy.
With this, can already use the semantic web query language, called SPARQL, to inquire about what it knows about me:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?property ?value
FROM <http://al3xandr3.github.io/foaf.rdf>
WHERE {
?me foaf:name "Alexandre Matos Martins" .
?me ?property ?value .
}
Why Another Online Profile?
How many times have you filled in your personal profile information on web sites? Google+, Facebook, YouTube, Yahoo!, MSN, Blogspot, Amazon, Twitter, LinkedIn, Flickr, Tumblr, Ebay, mySpace, hi5!, etc… How many times more we need to do it again?
The semantic web is about sharing data in an agreed upon format, so that the data can be easily linked-to and (re)used. Thus, once my profile is on the semantic web any new site that I sign-up for, can just read-in this data instead of asking me to fill it in.
Sharing data, in an agreed upon format, is an incentive for re-use and disincentive for wasteful duplication - #semanticweb
Adding the Site
Next step is to add the web site onto the semantic web.
Augmenting a web site content with semantic data, facilitates data sharing, essentially web pages became little standalone data repositories that can be understood by the semantic web tools.
The way to do it is simple enough; add (invisible)html properties into the existing web pages that specify (the semantics)meaning of the html elements.
These extra html tags, that add meaning to web pages, are defined in a microformat called RDFa, quoting Wikipedia:
RDFa defines how to embed RDF subject-predicate-object expressions within XHTML documents, it also enables the extraction of RDF model triples by compliant user agents.
For example, on the About section of my site, we can define rdfa tags saying “Alexandre Matos Martins” is my name and that I am of type Person, a link to my my foaf profile and my online accounts like Twitter and Skype:
Html:
<h2>About</h2>
<div about="http://al3xandr3.github.io/#me" typeof="foaf:Person" property="rdfs:seeAlso" content="http://al3xandr3.github.io/foaf.rdf">
<a rel="foaf:OnlineAccount" href="http://twitter.com/al3xandr3">twitter</a>
<a rel="foaf:skypeID" href="skype:al3x.martins?userinfo">skype</a>
</div>
With the rdfa tags on the site is then possible to use generic semantic web tools to query website data.
For example, to find the topics of a site(whats the site about), just aument the html list of topics of the site with rdfa tags, like so:
Html:
<a rel="dcterms:subject" href="/tags/SPARQL.html">SPARQL</a>
<a rel="dcterms:subject" href="/tags/data.html">data</a>
<a rel="dcterms:subject" href="/tags/abtesting.html">abtesting</a>
This allows, to Query It:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?subject
FROM <http://www.w3.org/2007/08/pyRdfa/extract?uri=http://al3xandr3.github.io/>
WHERE {
<http://al3xandr3.github.io> ?predicate ?subject .
?s dcterms:subject ?subject .
}
RDFa augments web pages as standalone data repositories that #semanticweb can understand, doubling as normal web pages, is like web scraping done right
Using It
Why is all this data useful? well for a more futuristic good use case check the Data, Data, Data! semantic web use case on Xmas.
But in the meanwhile, we can already play around with more mundane things, for example, predicting how likely is it, that i will write a twitter quote for any given day.
I collected a few of my twitter quotes on the quotes page and each quote has an rdfa date on it.
Html:
<blockquote about="/semanticweb.html#2011-12-21" property="dcterms:date" datatype="xsd:date" content="2011-12-21">
<p property='dcterms:description'>data,data,data! a #semanticweb use case on Xmas: <a href='http://al3xandr3.github.io/2011/12/18/data.html'>al3xandr3.github.com</a>
</p></blockquote>
<blockquote about="/semanticweb.html#2012-01-10" property="dcterms:date" datatype="xsd:date" content="2012-01-10">
<p property='dcterms:description'>Sharing data, in an agreed upon format, is an incentive for re-use and disincentive for wasteful duplication. #semanticweb
</p></blockquote>
etc...
So we can use the following sparql query to fetch directly from the quotes page, the dates and how many quotes, on each date, I’ve wrote:
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?date (count(?subject) AS ?total)
FROM <http://www.w3.org/2007/08/pyRdfa/extract?uri=http://al3xandr3.github.io/pages/quotes.html>
WHERE {
?subject dcterms:date ?date .
}
GROUP BY ?date
ORDER BY ?date
Then i see the day-of-the-week for each of those dates and sum up the number of quotes per day of the week.
Having this, I can calculate the probability(the expected value) for each day, and can then just lookup the probability for any given day.
For a full (a)live data experience this is implemented in javascript that fetches the data when this page is opened.
I use jquery .ajax to go fetch the data of the sparql query defined above, do some data manipulation, plot it using d3.js, and finally output the prediction.
Look at the source code of this page, to see how it works.
Quotes per day of the week:
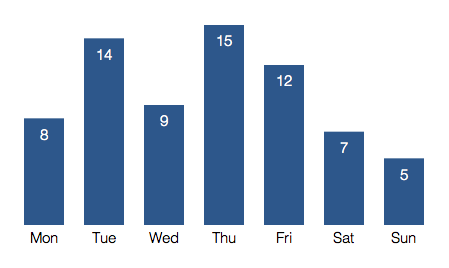
For example on Thursday is 21% likelly that I’ll tweet.